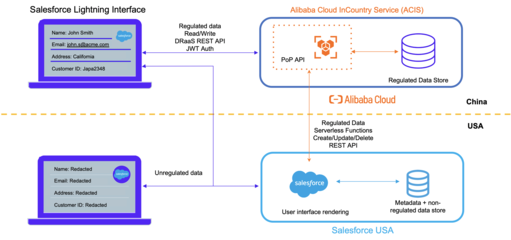
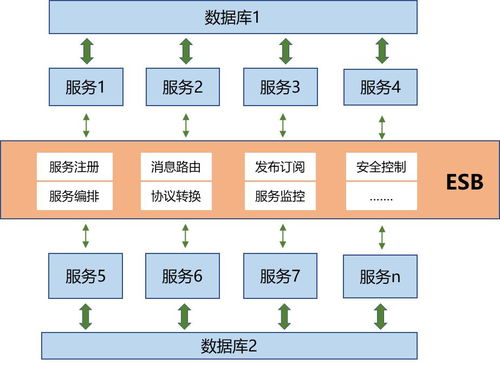
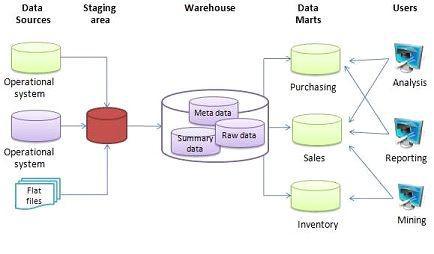
数据工程师的基石 关键数据结构与算法在数据处理服务中的应用
在当今数据驱动的时代,数据处理服务构成了现代企业技术栈的核心。作为支撑这些服务的关键构建者,数据工程师不仅需要掌握各种工具与平台,更需要深刻理解其背后的核心原理——关键的数据结构与算法。它们是高效、可靠、可扩展数据处理服务的基石。
一、 核心数据结构:数据处理的“容器”
数据工程师处理的数据规模庞大、形态多样,选择合适的数据结构是优化性能的第一步。
- 哈希表 (Hash Table):这是数据工程师工具箱中的“瑞士军刀”。无论是在流处理中进行实时去重(如使用布隆过滤器,一种基于哈希的概率数据结构),在ETL过程中进行快速的键值查找与关联(如Join操作),还是在构建查询索引时,哈希表以其平均O(1)的查找、插入性能而不可或缺。例如,Spark和Flink等分布式处理框架内部大量使用哈希表来管理状态和进行数据分区。
- 布隆过滤器 (Bloom Filter):一种节省空间的高效概率数据结构,用于快速判断一个元素“绝对不在集合中”或“可能在集合中”。在数据处理流水线中,它常用于前置过滤,例如在查询HBase或Cassandra前避免对不存在键的昂贵磁盘查找,或在日志分析中过滤掉已知的垃圾流量,大幅减少下游系统的负载。
- 跳表 (Skip List):一种可以替代平衡树的数据结构,实现相对简单,且支持高效的区间查询。在需要维护有序数据且并发访问频繁的场景下(如某些内存数据库或缓存系统),跳表因其易于并行化修改而受到青睐。
- 前缀树/字典树 (Trie):特别适用于需要前缀匹配的场景,例如搜索引擎的自动补全、IP路由表查找,或者在流数据处理中实时统计具有共同前缀的关键词热度。
- 位图 (Bitmap):一种极其紧凑的布尔数组表示法。在数据仓库和分析型数据库中,位图索引是加速等值查询和多重条件过滤的利器。对于低基数(取值种类少)的列,如“性别”、“状态”等,位图索引可以快速进行AND/OR位运算,实现高效的查询。
二、 核心算法:数据流动的“逻辑”
算法定义了数据如何被转换、聚合与计算,直接决定了处理逻辑的正确性和效率。
- 排序与归并算法 (Sorting & Merging):这是大规模数据处理的“心脏”。外部排序(如多路归并排序)使得处理远超内存容量的数据集成为可能。在MapReduce范式及数据仓库的排序-合并连接(Sort-Merge Join)中,它是关键步骤。了解这些算法有助于优化Shuffle阶段的性能,这是分布式处理中最昂贵的操作之一。
- 一致性哈希 (Consistent Hashing):分布式系统设计的核心算法之一。它解决了在缓存或数据库分片集群中,因节点增减而导致大量数据重新映射(即数据迁移)的问题。通过将数据和节点映射到同一个哈希环上,一致性哈希在节点变动时仅需迁移环上相邻部分的数据,极大提升了分布式数据处理服务的可扩展性和稳定性。Cassandra、DynamoDB等分布式数据库均依赖此算法进行数据分区。
- 窗口化算法 (Windowing Algorithms):流处理服务的核心。无论是处理固定时间窗口、滑动窗口还是会话窗口,高效的窗口管理(如水位线机制处理乱序数据)和窗口内聚合计算(如使用增量聚合或全量缓存)算法,是实现实时指标统计(如每分钟交易额)、监控告警的基础。Apache Flink等流处理引擎对此有深刻的算法实现。
- 图遍历与路径算法 (Graph Traversal):随着关系数据和分析的普及,图处理变得日益重要。广度优先搜索(BFS)、深度优先搜索(DFS)以及用于最短路径的迪杰斯特拉(Dijkstra)算法等,是进行社交网络分析、欺诈检测(识别循环交易)、推荐系统(基于图传播)的基础。
- 采样与近似算法 (Sampling & Approximation):在面对海量数据时,有时精确答案并非必需,快速得到一个近似结果可能更有价值。蓄水池采样算法用于从无限数据流中随机采样;HyperLogLog算法用于在极小空间内估算巨大数据集的基数(去重计数)。这些算法在实时监控、大数据探查和快速决策中应用广泛。
三、 数据结构与算法在数据处理服务中的综合应用
一个高效的数据处理服务,是数据结构与算法的精妙组合。例如:
- 一个实时风控服务:可能使用布隆过滤器快速过滤掉绝对安全的请求,用哈希表存储和维护实时更新的用户行为计数(用于阈值判断),利用窗口化算法统计用户最近一分钟的交易频率,并可能使用图算法来分析交易网络中的关联风险。
- 一个推荐系统数据处理管道:可能使用一致性哈希来对用户画像数据进行分片存储,使用排序归并算法来整合用户的历史行为和实时点击流,并利用图模型进行物品的协同过滤计算。
###
对于数据工程师而言,深入理解这些数据结构与算法,并非是为了应对学术挑战,而是为了解决实际生产环境中的性能瓶颈、设计出高吞吐低延迟的数据管道、并确保数据处理服务在面对日益增长的数据规模时依然稳健。它们是数据工程师将原始数据转化为高价值信息服务的底层引擎和艺术所在。掌握它们,意味着能够更自信地驾驭大数据技术的浪潮,构建真正强大可靠的数据处理基础设施。
如若转载,请注明出处:http://www.dlmkhjc.com/product/71.html
更新时间:2026-04-14 06:42:57